
¿Para qué nacieron las Computadoras? Para resolver problemas. Sí. Ya son legendarias las aventuras de Alan Turing, su equipo de trabajo y todos los esfuerzos por parte del gobierno británico para descifrar o más bien decriptar los mensajes generados con la máquina "Enigma" de los nacionales socialistas alemanes (nazis).

Son precisamente esos algoritmos lo que hace que un grupo de personas, los Programadores, puedan "ecribir" Programas de Cómputo y que estos al ejecutarse en el Hardware, realmente le den sentido a las Computadoras.
Durante mucho tiempo, sin importar el lenguaje de cómputo, se seguían los lineamientos y cánones de la Programación en Cascada.
La Programación en Cascada
Más comúnmente conocida como el modelo de desarrollo de software en cascada, es una metodología secuencial que se ha utilizado tradicionalmente en la ingeniería de software. Este modelo se caracteriza por una serie de fases claramente definidas y ordenadas, donde cada fase debe completarse antes de pasar a la siguiente. Aquí te detallo sus características principales y cómo se desarrolla:
Secuencialidad: El proceso sigue una secuencia lineal desde el inicio del proyecto hasta su conclusión, sin retroceder a fases anteriores.
Estructura Fija: Las fases del proyecto son fijas y se completan una tras otra en orden específico: Requisitos, Diseño, Implementación, Verificación, y Mantenimiento.
Documentación Completa: Cada fase produce documentos que sirven como entrada para la siguiente fase. Esto significa que antes de escribir código, se realiza una extensa documentación de los requisitos y el diseño.
Revisiones y Aprobaciones: Al final de cada fase, el trabajo realizado se revisa y debe ser aprobado antes de pasar a la siguiente etapa.
Las Fases del Modelo en Cascada incluyen:
- Análisis de Requisitos: Se identifican las necesidades del sistema y se documentan de manera detallada. Es la base para el diseño del sistema.
- Diseño del Sistema y del Software: Basándose en los requisitos, se elabora una arquitectura de cómo el software funcionará internamente y en interacción con otros sistemas o con el usuario.
- Implementación y Codificación: Los diseñadores comienzan a escribir el código del software según las especificaciones del diseño.
- Pruebas: El software se prueba para identificar y corregir errores. Se verifica que cumpla con los requisitos especificados.
- Despliegue: Una vez que el software ha sido probado y se considera listo, se instala o se libera para su uso.
- Mantenimiento: Después del lanzamiento, el software entra en una fase de mantenimiento para corregir errores no identificados previamente o para realizar actualizaciones.
Ventajas:
- Predecible: Las etapas y resultados están claramente definidos, lo que facilita la planificación y el presupuesto.
- Estructura: La metodología en cascada es fácil de entender y seguir, especialmente para proyectos simples y pequeños.
- Rigidez: La dificultad para volver a fases anteriores puede resultar en problemas si los requisitos cambian durante el desarrollo.
- Retrasos en la Prueba: Las pruebas se realizan al final del ciclo de vida, lo que puede resultar en la detección tardía de errores fundamentales.
- Dificultad con Requisitos Complejos o Cambiantes: No es ideal para proyectos donde los requisitos no están bien definidos desde el principio o son propensos a cambiar.

El modelo de programación basado en microservicios representa un enfoque arquitectónico para el desarrollo de aplicaciones. En lugar de construir una aplicación monolítica grande (o inmensa en ocasiones), el enfoque de microservicios descompone o más bien parte la aplicación en componentes más pequeños y manejables, conocidos como microservicios. Estos microservicios son independientes entre sí, cada uno ejecutando un proceso único y gestionando una parte específica de la funcionalidad de la aplicación.
A continuación enumeramos cuáles son las características principales, cómo funcionan, y las ventajas y desventajas de este modelo basado en microservicios.
Especialización: Los microservicios se centran en una sola tarea o proceso, siguiendo el principio de responsabilidad única. Esto facilita la comprensión, el desarrollo y el mantenimiento del código.
Comunicación a través de API: Los microservicios interactúan entre sí mediante interfaces de programación de aplicaciones (APIs), generalmente sobre protocolos HTTP/HTTPS con patrones de comunicación REST o GraphQL.
Tecnología Diversa: Cada microservicio puede ser desarrollado utilizando el lenguaje de programación, base de datos, o tecnología de almacenamiento más adecuado para su función específica.
- Una aplicación basada en microservicios se compone de varios servicios pequeños que se comunican a través de la red.
- Cada servicio tiene su propia base de datos y lógica de negocio, lo que permite su desarrollo y escalabilidad de manera independiente.
- Los servicios se despliegan típicamente en contenedores, lo que facilita su replicación y gestión a través de plataformas de orquestación como Kubernetes.
- Flexibilidad Tecnológica: Permite el uso de diferentes tecnologías y lenguajes de programación según las necesidades específicas del servicio.
- Escalabilidad: Los servicios pueden escalarse independientemente, mejorando el uso de recursos y la capacidad de respuesta ante cargas variables.
- Resiliencia: El fallo en un microservicio no necesariamente causa un fallo en toda la aplicación, lo que mejora la disponibilidad y confiabilidad del sistema.
- Facilita la Integración Continua y la Entrega Continua (CI/CD): La independencia de los servicios facilita la actualización, el testing y el despliegue rápido y frecuente de nuevas características.
- Complejidad de Gestión: El manejo de múltiples servicios y su intercomunicación puede resultar en una complejidad operativa significativa.
- Consistencia de Datos: Mantener la consistencia a través de los servicios puede ser desafiante, especialmente en transacciones que abarcan múltiples servicios.
- Latencia: La comunicación entre servicios a través de la red puede introducir latencia.
- Sobrecarga de Desarrollo: El diseño e implementación inicial pueden requerir más trabajo comparado con una aplicación monolítica debido a la planificación de la interacción entre servicios.

Queremos aquí hacer una pausa, pues como veremos más delante en esta entrada, Microservicios es un Modelo de Programación, pero los Contenedores son una manera de llevar a la práctica este modelo de programación y no por ello presentar las mismas desventajas.
¿Qué SÍ son y qué NO son los Contenedores?

- Sí son entornos aislados: Los contenedores encapsulan una aplicación y todas sus dependencias en un entorno aislado del resto del sistema, lo que garantiza que funcionen de manera consistente y sin conflictos con otras aplicaciones.
- Sí ofrecen portabilidad: Los contenedores son portátiles y pueden ejecutarse en cualquier entorno que admita el motor de contenedores utilizado, lo que facilita el desarrollo, la prueba y la implementación de aplicaciones en diferentes entornos de forma consistente.
- Sí son eficientes: Los contenedores son ligeros y rápidos de crear y destruir, lo que los hace ideales para implementaciones rápidas y escalables de aplicaciones.
- Sí son escalables: Los contenedores pueden escalarse horizontalmente fácilmente para satisfacer las demandas cambiantes de la carga de trabajo, lo que los hace ideales para aplicaciones en la nube y en entornos distribuidos.
- No son máquinas virtuales: A diferencia de las máquinas virtuales, los contenedores no incluyen un sistema operativo completo. En su lugar, comparten el kernel del sistema operativo subyacente y solo encapsulan las bibliotecas y dependencias necesarias para ejecutar la aplicación.
- No son un reemplazo de la virtualización tradicional: Aunque los contenedores ofrecen muchas ventajas en términos de eficiencia y portabilidad, no reemplazan por completo la virtualización tradicional. Ambas tecnologías pueden coexistir y ofrecer beneficios complementarios en entornos de desarrollo y producción.
- No son una solución de seguridad completa: Aunque los contenedores ofrecen un cierto grado de aislamiento y seguridad, no son una solución de seguridad completa por sí solos. Se deben implementar medidas adicionales, como políticas de acceso y control de seguridad, para proteger los contenedores y las aplicaciones que contienen.


- Definición de contenedores y su importancia en el desarrollo de software moderno.
- Diferencias entre contenedores y máquinas virtuales.
- Historia y evolución de la tecnología de contenedores.
- Instalación y configuración de Docker en diferentes sistemas operativos.
- Creación y gestión de contenedores Docker.
- Uso de imágenes de Docker y registro de Docker Hub.
- Redes y almacenamiento en Docker.
- Introducción a Kubernetes y su arquitectura.
- Instalación y configuración de un clúster de Kubernetes.
- Despliegue y escalado de aplicaciones en Kubernetes.
- Gestión de recursos y monitoreo en Kubernetes.
- Desarrollo de aplicaciones utilizando Docker y Docker Compose.
- Uso de Docker en entornos de desarrollo local y en la nube.
- Integración de contenedores en pipelines de integración continua/despliegue continuo (CI/CD).
- Principios de seguridad en contenedores.
- Mejores prácticas para la creación de imágenes seguras.
- Configuración de políticas de acceso y control de seguridad en Kubernetes.
- Estrategias para optimizar el tamaño y el rendimiento de las imágenes de Docker.
- Configuración de recursos y límites en contenedores.
- Estrategias de almacenamiento y gestión de datos en contenedores.
- Aplicaciones de contenedores en diferentes industrias y sectores.
- Estudios de casos de empresas que han adoptado contenedores con éxito.
- Prácticas recomendadas y lecciones aprendidas de implementaciones reales.
- Udemy: Ofrece una amplia variedad de cursos sobre Docker, Kubernetes y contenedores en general, impartidos por instructores expertos.
- Coursera: Tiene cursos y especializaciones en contenedores ofrecidos por universidades y empresas líderes en tecnología.
- LinkedIn Learning: Ofrece una amplia gama de cursos y tutoriales sobre Docker, Kubernetes y desarrollo de contenedores.
- Pluralsight: Tiene cursos especializados en contenedores y orquestación de contenedores, diseñados para profesionales de la tecnología.
- edX: Ofrece cursos en línea gratuitos y de pago sobre contenedores, impartidos por universidades y organizaciones académicas.
- Documentación oficial de Docker y Kubernetes: Ambas comunidades ofrecen una amplia documentación en línea que cubre todos los aspectos de sus respectivas tecnologías.
- Tutoriales y guías en blogs y sitios web: Hay muchos blogs y sitios web que ofrecen tutoriales y guías gratuitas sobre Docker, Kubernetes y contenedores en general.
- GitHub: Hay numerosos repositorios en GitHub con ejemplos de código, proyectos y recursos de aprendizaje relacionados con contenedores.
- Certificaciones oficiales de Docker y Kubernetes: Tanto Docker como Kubernetes ofrecen programas de certificación oficial que pueden ayudar a validar tus habilidades en contenedores.
- Cursos especializados en plataformas de capacitación en línea: Algunas plataformas ofrecen cursos específicos para la preparación de certificaciones en Docker y Kubernetes.
- Participar en comunidades en línea, como foros, grupos de usuarios y canales de Slack relacionados con Docker y Kubernetes, puede ser una forma útil de aprender y compartir conocimientos con otros profesionales de contenedores.




- Para Linux: Encontraremos instrucciones específicas para la distribución en la documentación oficial de Docker.
- Para Windows y macOS: Docker Desktop es la opción recomendada. Hay que asegurarse de cumplir con los requisitos del sistema.
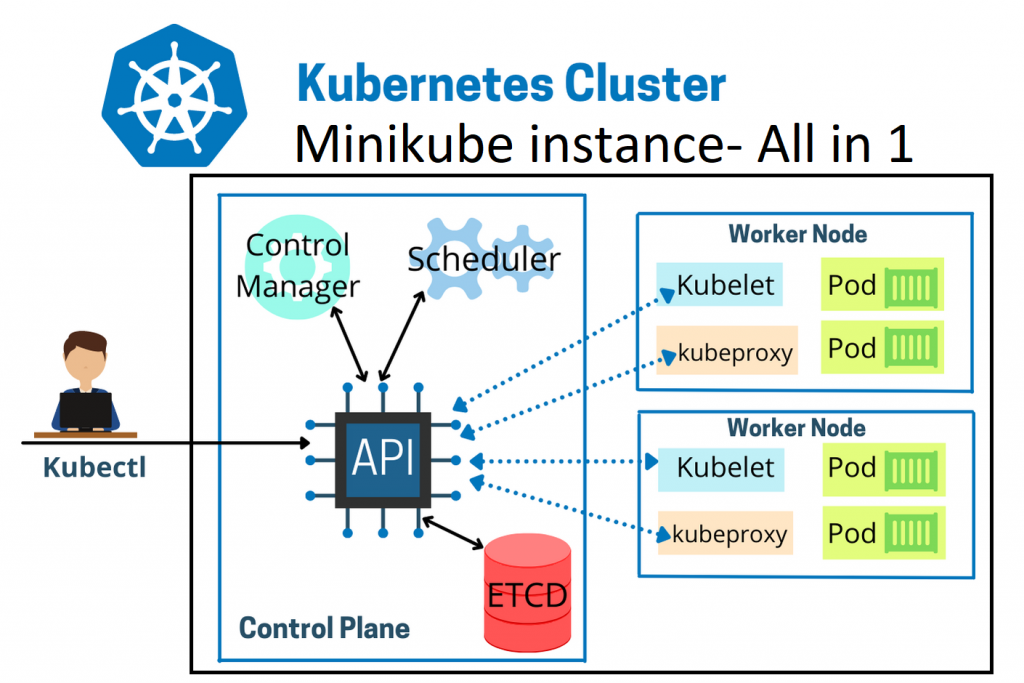
- Sencillez: Minikube inicia un clúster de Kubernetes de un solo nodo dentro de una máquina virtual (VM) en la máquina de escritorio o la laptop, lo que hace que sea fácil de instalar y ejecutar.
- Compatibilidad: Funciona en sistemas operativos Linux, Windows y macOS.
- Flexibilidad: Soporta diversas herramientas de virtualización, incluyendo VirtualBox, KVM, HyperKit, y más. También puede ejecutarse directamente en contenedores Docker si preferimos evitar usar una VM.
- Desarrollo Local: Proporciona un entorno ideal para aprender Kubernetes y experimentar con contenedores sin incurrir en costos de infraestructura de nube.
- Herramientas de Desarrollo: Minikube incluye características útiles para el desarrollo, como un Dashboard de Kubernetes, soporte para carga de configuración y volúmenes persistentes, y la capacidad de emular redes y condiciones de entorno específicas.
- Aprendizaje de Kubernetes: Por ser un clúster de Kubernetes real, aunque sea de un solo nodo, Minikube es una excelente herramienta para aprender cómo funciona Kubernetes y cómo se despliegan y gestionan las aplicaciones en él.
- Desarrollo de Aplicaciones: Los desarrolladores pueden usar Minikube para desarrollar y probar aplicaciones en un entorno de Kubernetes local antes de desplegarlas en un entorno de producción o en la nube.
- Pruebas de Integración y Funcionalidad: Permite a los equipos de desarrollo probar nuevas características, configuraciones, y más, en un entorno controlado y fácilmente reproducible.
¿Está Usted listo para comenzar con los contenedores?







