

Una constante de todo aquello que trasciende es La Evolución. Y Cómputo, Sistemas, Informática, etc. no son la excepción. Es entonces y gracias a la Convergencia Informática que ahora existen las Tecnologías de la Información. Vale la pena entonces para comenzar y ubicarnos dentro de un contexto, revisar:
¿Cómo ha sido la evolución de lo que ahora conocemos como Tecnologías de la Información?
La evolución de las Tecnologías de la Información (TI) ha sido un camino bastante interesante que abarca desde los mainframes hasta la infraestructura hiperconvergente. Esto ha sido un proceso marcado por avances significativos en hardware, software y paradigmas de diseño. Aquí te presento una visión general de esta evolución:
Mainframes (1950-1970):

Los sistemas operativos como IBM OS/360 dominaron este período y fueron diseñados para soportar múltiples usuarios y aplicaciones simultáneamente.
Era de la Computadora Personal (PC) y Cliente-Servidor (1980-1990):
La introducción de las PC permitió una computación más accesible y distribuida. La arquitectura cliente-servidor surgió, donde los recursos de cómputo se dividían entre los clientes (PC) y los servidores dedicados.
Los sistemas operativos como Linux y Windows ganaron popularidad en este período, permitiendo una interfaz gráfica de usuario y una mayor flexibilidad en el software.
Virtualización y Consolidación (2000-2010):
La virtualización se convirtió en una tecnología clave, permitiendo la ejecución de múltiples Máquinas Virtuales independientes sobre un solo Servidor Físico, cada una con su sistema operativo y aplicaciones.
Surgieron soluciones de almacenamiento y redes definidas por software para aumentar la flexibilidad y la eficiencia de los recursos.
La consolidación de servidores y la optimización de recursos se convirtieron en objetivos clave para reducir costos y mejorar la utilización de recursos.
Nube y Computación Distribuida (2010 en adelante):

Los servicios de infraestructura como servicio (IaaS), plataforma como servicio (PaaS) y software como servicio (SaaS) se convirtieron en modelos populares de implementación de aplicaciones.
La automatización y la orquestación de la infraestructura se volvieron esenciales para la gestión eficiente de los entornos en la nube.
Hiperconvergencia (2010 en adelante):
La hiperconvergencia integra cómputo, almacenamiento, redes y virtualización en una única plataforma definida por software.
Esta arquitectura simplifica la gestión y el despliegue de infraestructura, reduciendo la complejidad y los costos operativos.
La hiperconvergencia permite una mayor flexibilidad y escalabilidad al tiempo que mejora el rendimiento y la eficiencia de los recursos.
En resumen, la evolución de las TI desde los mainframes hasta la infraestructura hiperconvergente ha sido impulsada por la necesidad de mejorar la eficiencia, la flexibilidad y la escalabilidad de los recursos informáticos, adaptándose a los cambios en las demandas empresariales y tecnológicas. Cada etapa ha traído consigo avances significativos que han dado forma al panorama actual de la tecnología de la información.
¿Quién y cúando acuñó por primera vez la palabra "Hiperconvergencia"?
La palabra "hiperconvergencia" comenzó a ganar popularidad en la industria de la tecnología a principios del siglo XXI, especialmente con el surgimiento de soluciones de infraestructura convergente y virtualización avanzada. Sin embargo, no hay un único individuo o evento específico que pueda atribuirse como el origen exacto de la palabra "hiperconvergencia".
En general, el término "hiperconvergencia" evolucionó de la convergencia de múltiples tecnologías de infraestructura en una sola plataforma integrada, y comenzó a ser utilizado por empresas de tecnología y expertos en la industria para describir este enfoque. Se puede decir que surgió gradualmente a medida que los proveedores de soluciones y los profesionales de TI buscaban términos para describir la convergencia de recursos de cómputo, almacenamiento y redes en una sola infraestructura.
Si bien no hay una fecha o persona específica que haya acuñado por primera vez la palabra "hiperconvergencia", su popularidad y adopción se han acelerado en los últimos años a medida que las organizaciones buscan simplificar la gestión de la infraestructura de TI y mejorar la eficiencia operativa.
¿Qué es la Hiperconvergencia?

- Almacenamiento
- Redes
- Virtualización
- Administración de datos y seguridad
Algo muy importante y que hace la gran diferencia gracias a la Hiperconvergencia, es que en lugar de tener componentes separados y silos de recursos, combina todo en una sola plataforma, generalmente basada en software "ad hoc" y hardware estándar. Esto simplifica la gestión, reduce la complejidad y los costos operativos, permitiendo una mayor flexibilidad y escalabilidad en entornos de centro de datos. La hiperconvergencia requiere y está orientada a la virtualización, lo que le profiere la capacidad de escalar recursos de manera eficiente y rápida es fundamental.
¿Qué SÍ es y qué NO es la Hiperconvergencia?
Qué SÍ es la Hiperconvergencia:
- Integración de Recursos: La hiperconvergencia es un enfoque de infraestructura de TI que integra computación, almacenamiento, redes y virtualización en una sola plataforma unificada.
- Software Definido por Usuario: Utiliza software definido por usuario para gestionar y orquestar todos los recursos de infraestructura desde una interfaz centralizada.
- Permite Escalabilidad Horizontal: La adición de nodos permite escalar horizontalmente, proporcionando una mayor capacidad de procesamiento, almacenamiento y red según sea necesario.
- Simplicidad Operativa: Simplifica la gestión y administración de la infraestructura de TI al consolidar recursos en una sola plataforma y proporcionar una interfaz unificada para la gestión.
- Eficiencia y Flexibilidad: Mejora la eficiencia operativa y la flexibilidad al permitir la asignación dinámica de recursos según las necesidades del negocio.
Qué NO es la Hiperconvergencia:
- NO se apega a la Arquitectura Tradicional de Centro de Datos: No se trata de la arquitectura tradicional de centro de datos donde los recursos de cómputo, almacenamiento y red son gestionados por separado.
- NO es una Solución de Almacenamiento Convergente: Aunque la hiperconvergencia incluye almacenamiento como uno de sus componentes, no se limita a ser simplemente una solución de almacenamiento convergente, ya que integra múltiples recursos en una plataforma unificada.
- NO está Limitada a un Proveedor Específico: Aunque varios proveedores de tecnología ofrecen soluciones hiperconvergentes, no está restringida a un solo proveedor. Puede haber múltiples opciones disponibles en el mercado, cada una con sus propias características y beneficios.
- NO es una Solución Única para Todos los Escenarios: Aunque la hiperconvergencia puede ser una opción viable para muchos casos de uso, puede no ser la solución óptima para todos los entornos de TI, especialmente aquellos que requieren configuraciones muy personalizadas o específicas.
¿Qué debe componer una solución Hiperconvergente?
Una solución hiperconvergente típicamente está compuesta por varios componentes que se integran en una plataforma unificada para proporcionar cómputo, almacenamiento, redes y virtualización. Aquí están los componentes clave que suelen componer una solución hiperconvergente:
Nodos Hiperconvergentes:
- Son servidores estándar equipados con recursos de cómputo, almacenamiento y redes.
- Estos nodos están preconfigurados y optimizados para trabajar juntos en un clúster hiperconvergente.
Hipervisor:
- El software de virtualización que permite ejecutar múltiples máquinas virtuales en los nodos hiperconvergentes.
- Los hipervisores comunes incluyen VMware vSphere, Nutanix Acropolis Hypervisor, Microsoft Hyper-V, KVM, etc.
Software de Gestión y Orquestación:
- Proporciona una interfaz centralizada para la gestión y administración de la infraestructura hiperconvergente.
- Permite la implementación, configuración, monitoreo y automatización de recursos.
Almacenamiento Distribuido:
- Utiliza el almacenamiento local de cada nodo para crear un único pool de almacenamiento distribuido.
- Las técnicas de replicación y redundancia garantizan la alta disponibilidad y la protección de los datos.
Redes Definidas por Software (SDN):
- Abstrae la capa de red para simplificar la configuración y gestión de redes en la infraestructura hiperconvergente.
- Proporciona funciones como enrutamiento, conmutación y segmentación de red de manera programática.
Recursos de Cómputo:
- Procesadores (CPU), memoria (RAM) y otros recursos de cómputo necesarios para ejecutar máquinas virtuales y aplicaciones.
Interconexión de Red:
- Conectividad de red entre los nodos hiperconvergentes para facilitar la comunicación y el acceso a los recursos.
- Puede incluir switches Ethernet y tecnologías de interconexión de alta velocidad como 10GbE, 25GbE, o 100GbE.
Capacidad de Escalabilidad:
- La capacidad de agregar nodos adicionales a medida que aumentan las demandas de recursos, permitiendo una escalabilidad horizontal.
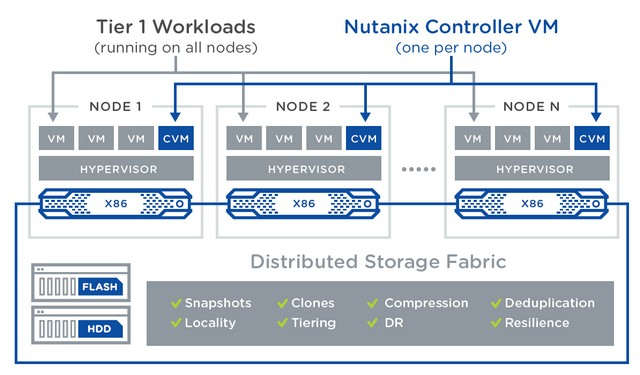
Algunas de las empresas más influyentes en el espacio de la hiperconvergencia incluyen:
- Nutanix: Empresa pionera en el desarrollo de soluciones hiperconvergentes. Introdujeron una plataforma que combina cómputo, almacenamiento y virtualización en una sola solución escalable.
- VMware: Ha sido un líder en virtualización y ha desarrollado soluciones como VMware vSAN y VMware vSphere, que forman la base de muchas plataformas hiperconvergentes.
- Dell EMC: Ofrece una amplia gama de soluciones hiperconvergentes bajo la marca Dell EMC VxRail, que integran hardware de servidor Dell EMC con software de VMware vSAN.
- Cisco: Ofrece soluciones hiperconvergentes a través de su plataforma HyperFlex, que combina hardware Cisco UCS con software de VMware o Hyper-V.
¿Qué libros hay disponibles para entender y aprender la Hyperconvergencia?
Hay varios libros disponibles que pueden ayudarte a comprender y aprender más sobre la hiperconvergencia y su implementación en entornos de tecnología de la información. Aquí hay algunos libros recomendados:
"Hyperconverged Infrastructure Data Centers: Demystifying the Black Box" de Sam Halabi y Faraz Shamim: Este libro ofrece una introducción detallada a la hiperconvergencia, cubriendo los conceptos básicos, la arquitectura, las ventajas y los desafíos de esta tecnología.
"Hyperconverged Infrastructure For Dummies" de Stefan Renner, René Koch y Lisa Person: Parte de la popular serie "For Dummies", este libro proporciona una visión general accesible de la hiperconvergencia, explicando cómo funciona y cómo puede beneficiar a las organizaciones.
"Hyperconverged Infrastructure Explained" de the Nutanix team: Nutanix es uno de los principales proveedores de soluciones hiperconvergentes, y este libro ofrece una visión detallada de su enfoque de la hiperconvergencia, sus productos y su impacto en la infraestructura de TI.
"VMware Hyper-Converged Infrastructure (HCI) Solutions" de Gurusimran Khalsa y Pete Flecha: Este libro se centra en las soluciones hiperconvergentes de VMware, como VMware vSAN y VMware Cloud Foundation, proporcionando una guía práctica para su implementación y gestión.
"Building a Future-Proof Cloud Infrastructure: A Guide to Hypeconverged Cloud Solutions" de Michael van Horenbeeck: Este libro explora cómo la hiperconvergencia puede ser utilizada como base para la construcción de infraestructuras de nube futuras, cubriendo aspectos como la seguridad, la escalabilidad y la eficiencia operativa.
¿Cuáles requerimientos de Tecnologías de la Información SÍ cuáles NO pueden satisfacerse con la Hiperconvergencia?

Qué requerimientos de TI SÍ pueden satisfacerse con la Hiperconvergencia:
Consolidación de Infraestructura: La hiperconvergencia puede satisfacer la necesidad de consolidar múltiples recursos de TI, incluyendo cómputo, almacenamiento y redes, en una sola plataforma unificada.
Escalabilidad y Flexibilidad: Permite escalar recursos fácilmente agregando nodos adicionales a medida que crecen las demandas de TI, proporcionando una mayor flexibilidad para adaptarse a las necesidades cambiantes del negocio.
Simplicidad Operativa: Simplifica la gestión y administración de la infraestructura de TI al proporcionar una interfaz unificada para gestionar todos los recursos desde un solo lugar.
Alta Disponibilidad y Tolerancia a Fallos: Ofrece capacidades integradas de alta disponibilidad y tolerancia a fallos, asegurando la continuidad del negocio y la protección de los datos críticos.
Implementación Rápida: Facilita la implementación rápida de nuevos recursos de TI mediante la automatización y la configuración predefinida, lo que acelera el tiempo de entrega de servicios.
Qué requerimientos de TI NO pueden satisfacerse con la Hiperconvergencia:
Requisitos de Rendimiento Demasiado Específicos: En algunos casos, los requerimientos de rendimiento extremadamente altos pueden no ser óptimamente atendidos por una infraestructura hiperconvergente, especialmente cuando se necesitan recursos altamente especializados o dedicados.
Personalización Extrema: Para casos en los que se requiere una alta personalización y configuración específica de los recursos de TI, la hiperconvergencia puede limitar las opciones en comparación con soluciones más tradicionales.
Compatibilidad con Todas las Tecnologías Existentes: Puede haber desafíos de compatibilidad con tecnologías existentes en el entorno de TI, especialmente si se utilizan sistemas heredados que no son fácilmente integrables en una infraestructura hiperconvergente.
Aplicaciones de Cómputo de Alto Desempeño: Aplicaciones que requieren Infraestructura de Cómputo de Alto Desempeño tienen requisitos que pueden no ser completamente satisfechos por una solución hiperconvergente.
Conclusión

La Hiperconvergencia es una opción viable para una amplia gama de requerimientos de TI, especialmente aquellos relacionados con la consolidación, escalabilidad, simplicidad operativa y alta disponibilidad. Sin embargo, puede no ser la solución óptima para casos que requieran personalización extrema, requisitos de rendimiento muy específicos o integración con tecnologías heredadas complejas.
Una solución hiperconvergente combina hardware estándar con software "ad hoc" o "ex profeso" para crear una infraestructura unificada y altamente integrada. Esta arquitectura simplifica la gestión, mejora la eficiencia y proporciona una mayor flexibilidad y escalabilidad en comparación con enfoques tradicionales de centro de datos.
¿Ahora sí está convencido de los inmensos beneficios que puede ofrecer la Hiperconvergencia para su Empresa u Organización?





























