

Imaginemos por un momento que nosotros, las empresas y toda organización educativa o de gobierno somos seres acuáticos que nos encontramos navegando a través de un enorme y basto océano de datos.
Ahora imaginemos que este maremágnum de datos contiene una enorme cantidad de nutrientes potenciales (datos que se pueden convier en información valiosa) al alcance de todo quien sepa deglutirlos.

Eso significaría que los sensores y sistemas de TI simplemente no están a la altura de la exploración e interpretación de los vastos océanos de datos en la que navegamos. Como consecuencia, la mayor parte de los datos que rodea las organizaciones hoy simplemente se ignora.

Esto puede resultar escandaloso, ya que si existiera una verdadera coordinación e inteligente explotación y/o minera de estos flujos de información, podríamos mejorar tanto los resultados individuales de cada paciente y una mayor planificación de las iniciativas y estrategias relativas a la salud.
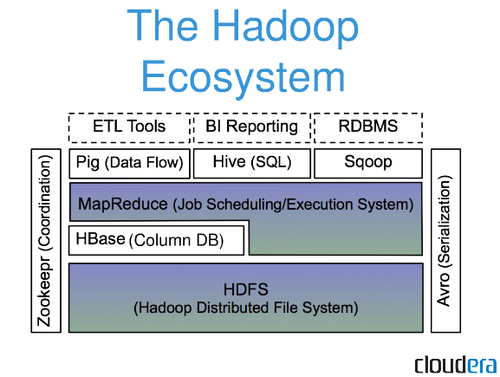
Debido a los problemas planteados por su volumen, la velocidad y la variedad, BigData exige nuevas soluciones tecnológicas. En la actualidad el líder en este campo es un proyecto de código abierto llamado Apache Hadoop.

Lo que hace Hadoop es básicamente distribuir el almacenamiento y procesamiento de grandes conjuntos de datos a través de grupos o clusters de servidores usando un modelo de programación simple.

Técnicamente, Hadoop se compone de dos elementos clave. El primero es el sistema de archivos distribuidos Hadoop (HDFS), que permite un alto ancho de banda basado en un clúster de almacenamiento, esencial para la computación de Bigdata.
La segunda parte de Hadoop es un marco de procesamiento de datos denominado MapReduce, el cual se basa en la tecnología de búsqueda de Google. Éste distribuye o "mapea" grandes conjuntos de datos en múltiples servidores.
Ahora bien, hablando de las implicaciones que BigData trae consigo, mientras que el volumen de datos ahora se mide en Terabytes, Petabytes e inclusive Exabytes, ahora no solamente tenemos enfrente un enorme desafío técnico sino también enormes oportunidades de negocio.
Por ello IBM menciona que -"BigData ... es una oportunidad para encontrar soluciones de comprensión en los nuevos tipos de datos emergentes para que las empresas, permitiendo respondar con mayor agilidad a las preguntas que en el pasado estaban fuera de su alcance"-.

En conclusión, BigData no es una moda o un nuevo "slogan" publicitario inventado por el área de Mercadotécnia de una empresa de Tecnologías de la Información. BigData es todo un reto que ya está presente en todas las empresas, entidades educativas y de gobierno a nivel global.
El planteamiento más importante de todo esto está en la respuesta a la pregunta: -"¿Desea Usted que su empresa u organización sea solo un organismo primitivo que deje pasar y eyecte información valiosa directamente por el escape?"-
Si la respuesta a la pregunta anterior es un rotundo NO, entonces lo que Usted necesita YA es alguna solución para aprovechar esta información, la cual se ha convertido en un enorme océano en el que todos estamos actualmente navegando.
Como sucede con todo concepto, solución y/o paradigma, BigData no es algo que se pueda dejar "a la ligera" en manos de pseudo expertos o peor aún de charlatanes. Se trata de algo que bien implementado puede literalmente alimentar a su empresa con datos de excelente calidad, propiciando un crecimiento saludable y sostenido.
Para terminar, conteste a Usted mismo esta pregunta: ¿Qué tan evolucionada está su infraestructura y soluciones de TI para poder digerir BigData?
No hay comentarios:
Publicar un comentario
Todos los derechos reservados.
Copyright © 2025.